
工具资源收藏
matlab资源
https://pan.isharepc.com/221578.html
//下载及安装全过程指南,实测ok
//验证数学算法等,还是非常好用的
draw.io绘制UML
https://www.draw.io/
//可以在线绘制
强大的在线学习网站
https://www.xuexi.cn/xxqg.html?id=0420ddf502ed4ec290f0b25f85b9ab72#fv0gxRElva
//学习强国,值得拥有
https://pan.isharepc.com/221578.html
//下载及安装全过程指南,实测ok
//验证数学算法等,还是非常好用的
https://www.draw.io/
//可以在线绘制
https://www.xuexi.cn/xxqg.html?id=0420ddf502ed4ec290f0b25f85b9ab72#fv0gxRElva
//学习强国,值得拥有
对UML建模有一个系统的学习记录。
UML通过图形化的表示机制从多个侧面对系统的分析和设计模型进行刻画。
为什么要用UML图?
通过使用UML使得在软件开发之前, 对整个软件设计有更好的可读性,可理解性,从而降低开发风险。同时,也能方便各个开发人员之间的交流。
UML提供了极富表达能力的建模语言,可以让软件开发过程中的不同人员分别得到自己感兴趣的信息。
Page-Jones 在《Fundamental Object-Oriented Design in UML》 一书中总结了UML的主要目的,如下:
共定义了10种视图,并将其分为如下4类。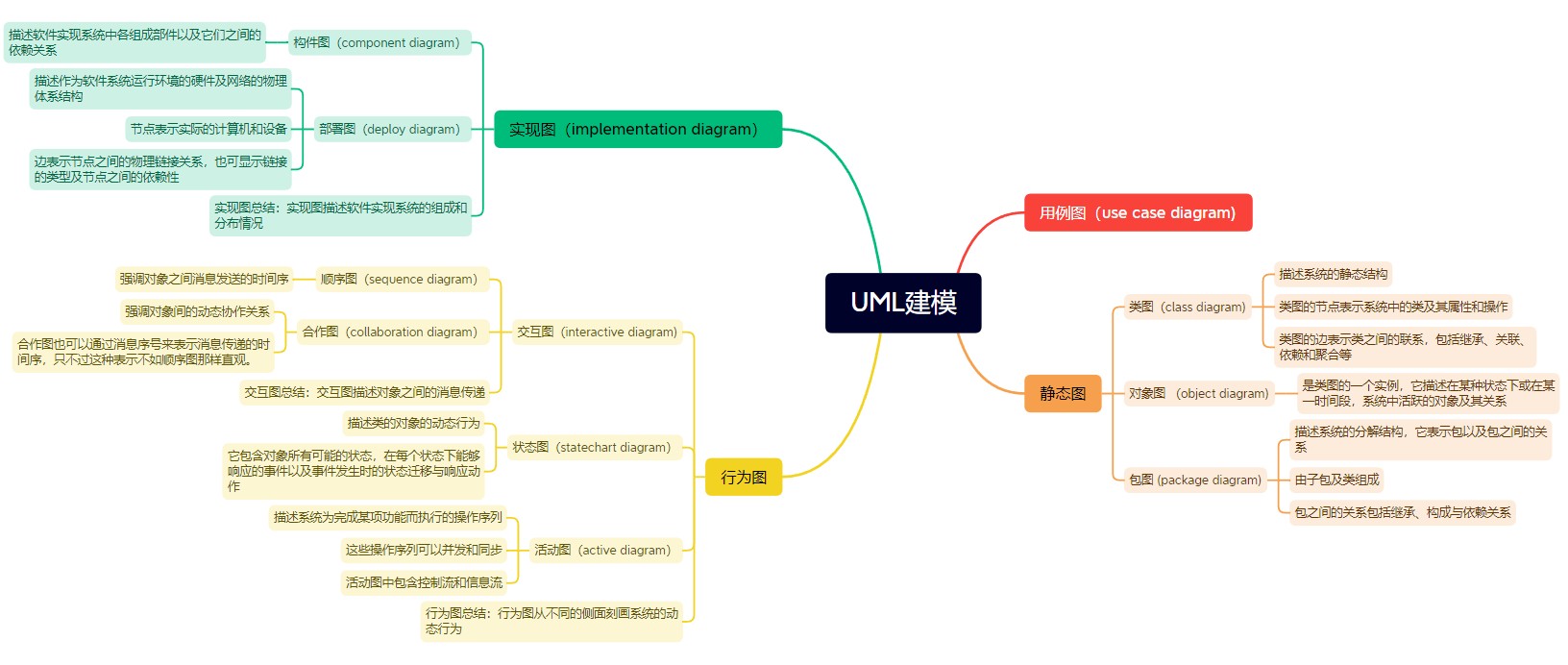
用例是代表系统中各相关人员之间就系统的行为所达成的默契。
软件的开发过程可以分为需求分析、设计、实现等阶段。
在需求分析阶段,用例是分析人员与客户沟通的工具和项目规模估算的依据;
在设计阶段,用例是系统功能设计的主要输入;
在实现阶段,用例是检测类行为正确性的文档。
因此,面向对象的软件开发过程是用例驱动的。
用例分析可以支持领域建模,以确保定义正确的需求,是保证OO软件开发成功的基础。
但要在具体的项目中灵活使用用例来捕获用户的需求并不是一件容易的事情,往往需要用户的经验、沟通能力、丰富的领域知识等。
本质上,用例分析是一种功能分解(functional decomposition)的技术,并未使用到面向对象思想。但用例是UML的重要部分,确定一个系统的用例才是开发OO系统的第一步,用例分析这步做得好,接着的交互图分析、类图分析等才有可能做得好,整个系统的开发才能顺利进行。
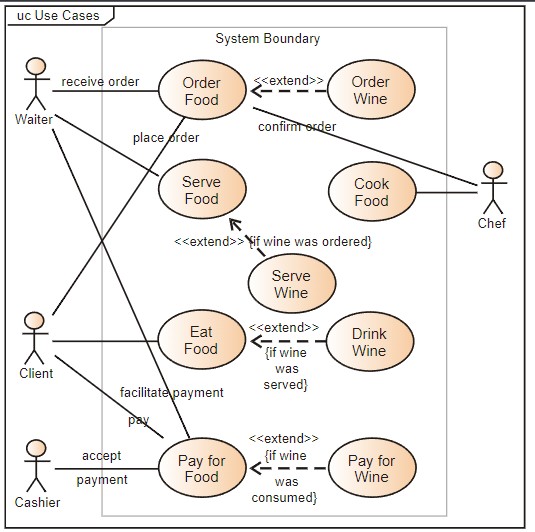
如上所示的UML用例图反映了顾客(角色,英语:actor)在餐馆(系统,英语:system)中的交互
(1)参与者
角色(actor)是指系统以外的、需要使用系统或与系统交互的东西,包括人、设备、外部系统等。
参与者其实是一个版型化的类,其版型是:
1 | <<Actor>> |

(2)用例间的关系
用例与参与者有关联(association)关系
用例之间也存在着:泛化(generalization)关系、包含(include)关系、扩展(extend)关系等
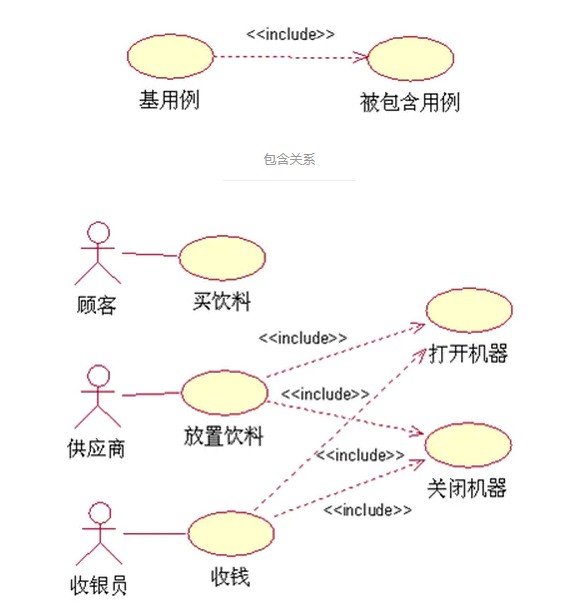
包含关系描述的是一个用例需要某种功能,而该功能被另外一个用例定义,那么在用例的执行过程中,就可以调用已经定义好的用例。
也可以说,其中一个用例的行为包含了另一个用例的行为。包含关系是依赖关系的版型,即包含关系是比较特殊的依赖关系。
版型符号:
1 | <<include>> |
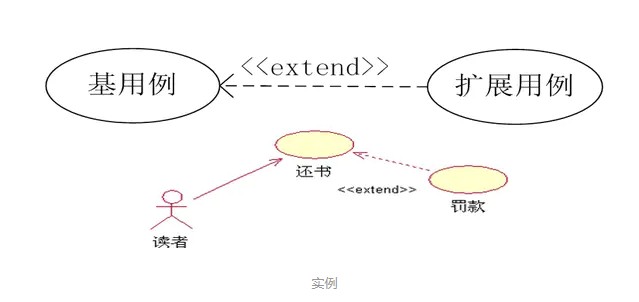
用一个用例(可选)扩展另一个用例(基本例)的功能,将一些常规的动作放在一个基本用例中,将可选的或只在特定条件下才执行的动作放在它的扩展用例中。
基本用例必须声明若干“扩展点”,而扩展用例只能在这些扩展点上增加新的行为和含义。扩展用例有更多的规则限制。
版型符号:
1 | <<extend>> |
(3)用例的描述
用例的描述是用例的核心部分,用例采用自然语言描述参与者与系统进行交互时双方的行为。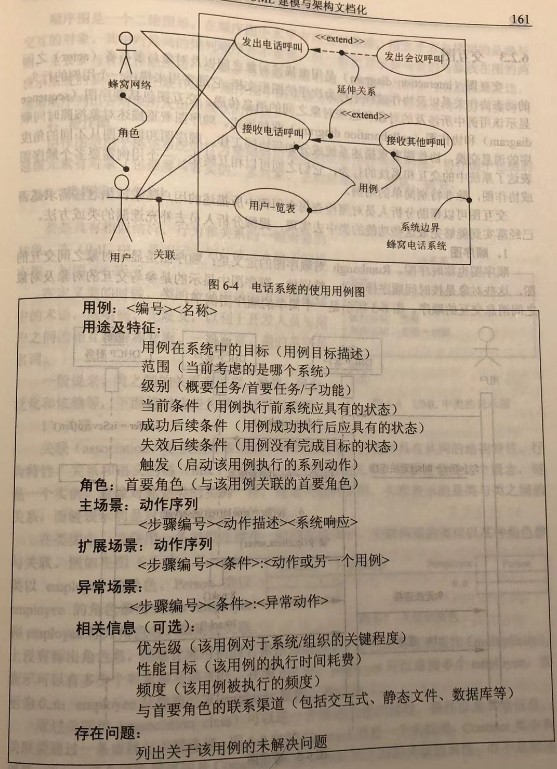
(4)系统边界system scope
系统边界system scope:确定系统的范围,边界是一个方框,用例在边界内,参与者在边界外;
UML (Unified Model Language) 统一建模语言
OMG (Object Management Group)
RTF (Revision Task Forces) 修订任务组
XMI (XML metadata Interchange)
DTD (Document Type Definition)
IDL (Interface Definition Language)
Object-Oriented 面向对象
Use Case 用例
domain modeling 领域建模
right requirement 正确的需求
extension use case 扩展用例
(1) UML已经取得重要成功,它已经成为软件工业中占支配地位的建模语言。并在许多领域的软件开发中得到应用。
(2) UML还存在着许多的问题,自它产生之日起就从未离开过匹配:用户和教授抱怨它内容庞大;学者认为它缺少一个精炼的核心和定义良好的外围,有些语义带着二义性;建模实践者认为它缺少支持自己领域建模要求的机制;工具开发商则因为规范本身的不确定性而产生理解上的偏差,它们对UML的自行诠释可能会误导用户。
(3) UML的关键问题是过于庞大和复杂,以及在语言体系结构、语义等方面存在理论缺陷。产生这些问题的一个重要原因是,在形成规范的过程中不得不照顾多种方法流派的观点和多家公司的利益。
系统的学习一下
(1)放大和缩放画面
Alt+鼠标滚轮
Alt+触摸板上下滑动
双击抓手工具,也可以快速实现适应屏幕大小
双击缩放工具,快速显示图像实际像素大小
Ctrl+”加号” 放大快捷键
Ctrl+”减号” 缩小快捷键
点击“窗口”菜单,选择导航器,也可以快速缩放图像
(2)新建空白项目
Ctrl+N
(3)修改图像大小
Ctrl+Alt+I
(4)打开文档
Ctrl+O
(5)存储文档
Ctrl+S
另存为
Ctrl+Shift+S
(6)关闭文档
Ctrl+W
(7)打开首选项
Ctrl+K
这里可以修改历史记录、暂存盘等
(8)打开快捷键菜单
Ctrl+Shif+Alt+K
(9)新建图层
Ctrl+Shift+N
(10)移动图层的顺序
Ctrl+[ 选中的图层向下移动
Ctrl+] 选择的图层向上移动
(5)拷贝图层
鼠标选中某个图层,按住Alt键不松,一直拖拽到想要的位置,看到鼠标变成双箭头,然后松开后就会发现已经复制了目标图层;
Ctrl+J也可以复制选中的图层
Alt+拖拽感兴趣的图层对象,也可以复制图层
(6)删除图层
鼠标选中某个图层,按Delete键即可
(7)召唤抓手工具
长按空格键不松 可以直接转换为抓手工具
(8)召唤移动工具
V 快捷键
(9)移动图层
可以按方向键,上下左右微调
Shift+上下左右 上下左右移动速度变快
(10)召唤选区工具
M 快捷键
(11)隐藏选区的蚂蚁线
Ctrl+H 按一次隐藏,再按一次显示
(10)剪切图层的部分内容
Ctrl+Shift+J 会将选区内的内容挖走
DEL也可以删掉选区内的内容
(11)快速画直线
B 快捷键切换到画笔工具
按住Shift键,绘制的时候是直线
(12)快速召唤拾色器
画笔状态下,按住Alt键不放,会由画笔切换成拾色器
当拾色器移动到想要吸取的颜色上,鼠标左键点击一下,即可将画笔吸取到这个颜色
(13)改变画笔大小快捷键
“[“ 左中括号,画笔变小
“]” 右中括号,画笔变大
(14)改变画笔硬度
shift+ “[“ 左中括号,硬度变小
shift+ “]” 右中括号,硬度变大
(15)橡皮擦工具
E 快捷键
(16) 图章工具
太牛了,这个工具实在是太牛了
按住Alt键,鼠标光标变成靶心,表示可以寻找仿制源了,
寻找到要复制的对象之后,点击一下鼠标左键,光标从靶心状态恢复,就表示已经取样到了。
取样后就可以按照画笔用法来涂抹出仿制对象了。
(17) 填充命令
Shift+F5
如果有选区的话,还可以配合“内容识别”功能,智能填充
(1) 图像文件格式
PSD 是ps软件的原始保存格式
PSB 是新格式
JPG 是广泛应用于互联网
GIF 动态图
(2) 像素概念![]()
(3) 图层
什么是图层?
图层简单来说就是图像的层次。
(4) 是否选择“细微缩放”
如果勾选了“细微缩放”,那点击放大镜(缩小镜)时,可以看到流畅的快速放大(或缩小)
如果不勾选“细微缩放”,点击放大镜之后,可以按住鼠标画一个矩形框,矩形框里的内容会被局部放大
(5) 缩放工具
缩放工具是为了更好的观察细节,并不会对图像进行改变
(6) 移动工具
移动工具可以多文件间拖拽图层对象
比如2个图像A.jpg和B.jpg
可以将B.jpg的图层,用移动工具拖拽到A.jpg文件的名字上,待到页面切换到A.jpg,看见鼠标出现加号,就可以将B.jpg中的那个图层拖拽到A.jpg的图像文件上。
如果A.jpg和B.jpg文档大小相同,想把B.jpg中的某个图层拖拽到A.jpg中,而且位置和B.jpg中一样。
那么,要先按住Shift不松,然后一直拖拽B.jpg里的那个图层放到A.jpg,看到鼠标出现加号后再松开Shift,即可。
移动工具针对当前被选中的图层,可以随意移动位置。
(7) 显示变换控件
勾选显示变换控件,就能对图层对象进行变换
比如放大缩小旋转等变换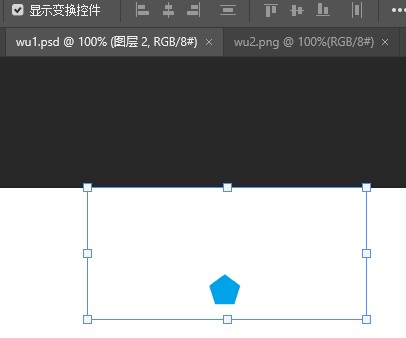
(8) 选区
选区内像素可被编辑,可被移动
选区以外不可修改
按住Ctrl键,点击图层缩略图,可以载入图层上的选区
(9) 羽化
羽化使得选区边缘柔和过渡
(10) 磁性套索
可以自动识别边缘
(11) 魔棒工具
非常适合快速抠图
根据颜色,快速制作选区,然后根据需求反选,“添加矢量蒙版”快速抠图
(12) 快速选择工具
非常重要的抠图工具
(13) 画笔工具
点击前景色,选择喜欢的颜色,即可切换画笔的颜色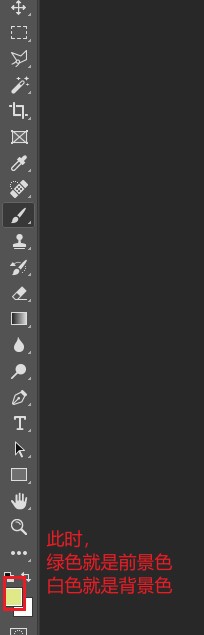
画笔工具可以载入(素材画笔),自制画笔
(14) 工具预设
(15) 喷枪样式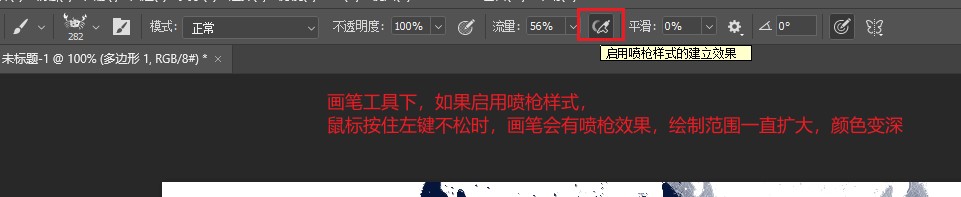
使用喷枪样式,按住鼠标左键不松,颜色会变多
(16) 红眼工具
眼睛在闪光灯作用下会扩张,而毛细血管会呈现出红色。
而红眼工具可以快速的将红眼消掉。
使用红眼工具在红眼上框一下就可以了。
(17)渐变工具
渐变工具,一般是通过点线拖拽使用。
(18)自由变换
Ctrl+T
会在选中的图层,出现一个自由变换的框,这个框是这个图层的内容的最大外接矩形。
Ctrl+Shift+T
会再次应用变换,应用上次的变换效果
Ctrl+Shift+Alt+T
会再次应用变换,而且复制图层,效果如下
变动参考点
按住Alt不松,鼠标会变成带移动符号的,此时鼠标点击一个地方,那个地方就会变成新的参考点。
如下图所示,这里的显示的x,y坐标值,其实就是参考点的像素坐标。
按住Shift键,是相对参考点的变换。
按住Shift+Alt键,可以组合变换,镜像翻转等效果都可以实现。
Ctrl+Z 撤销各种操作。
(19)像素图像(位图)的缩放
放大图像
增加的像素,是通过插值计算获取的。
缩小图像
会删减像素信息。
(20)颜色通道
RGB模式的图像,有三个通道
其他模式下,有不同的通道数。
更改模式设置的操作如下: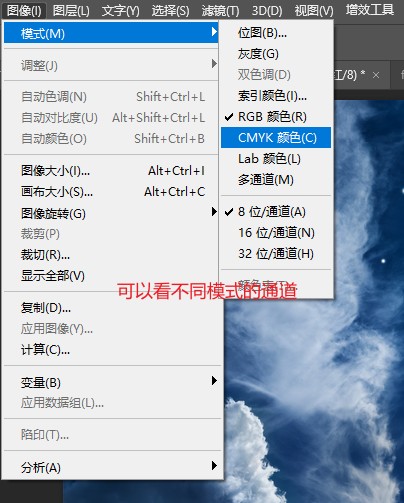
Alpha通道
透明度
记录不同区域的透明度信息的特殊图层
黑色:不包含像素信息,代表着透明,黑色0;
白色:表示100%的像素覆盖,代表着此处是不透明的,白色255;
灰阶:像素值1-254,代表着半透明(最重要);
(21)蒙版
图层蒙版编辑状态下,对于的就是一个临时的Alpha通道
如何进入蒙版的编辑状态?
选中蒙版,点击一下,就激活了。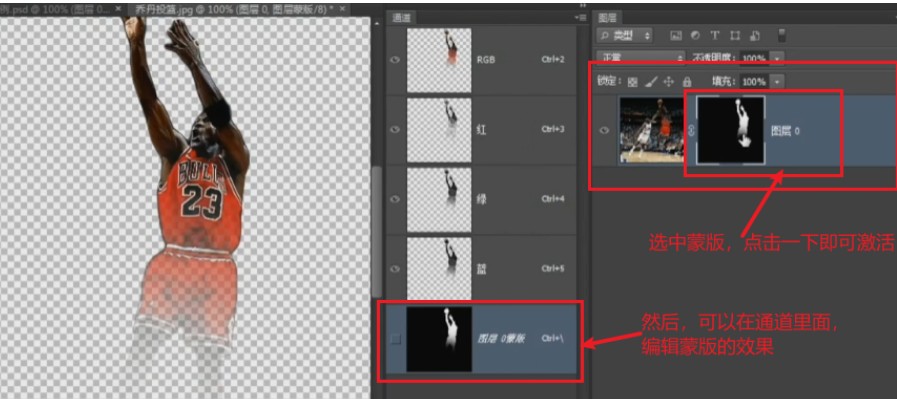
快速蒙版就是一个临时的Alpha通道
(22)图层链接
按住Ctrl键,选中多个图层的缩略图,然后点击图层面板下的链接按钮,就可以将多个图层链接起来。
图层链接可以多图层统一移动变换。
图层链接,只是链接的移动和变换,其他在各个图层上的绘制操作等等,都是互不干扰互不影响的。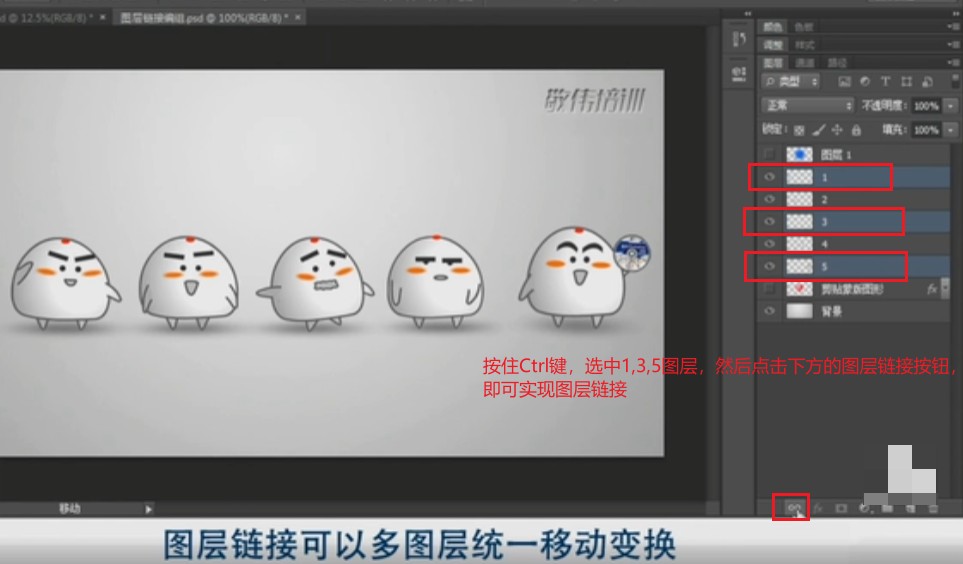
(23)图层编组
创建图层编组方法一:
按住Shift键,选中几个图层,然后点击创建新组按钮,就可以将图层编组,并且那几个被选中的图层都会被创建到那个分组里。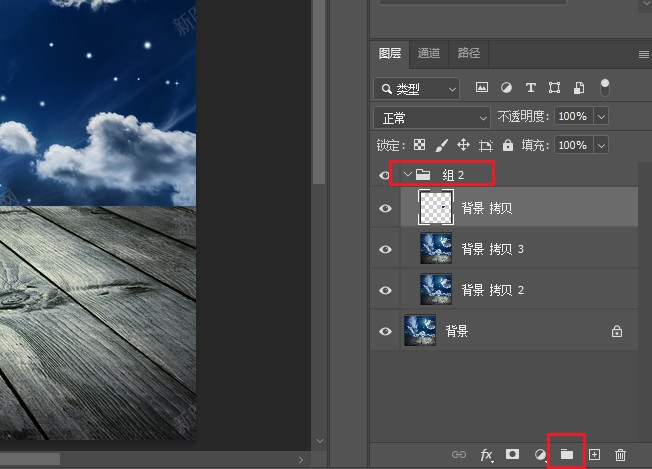
创建图层编组方法二:
按住Alt键,然后点击创建新组按钮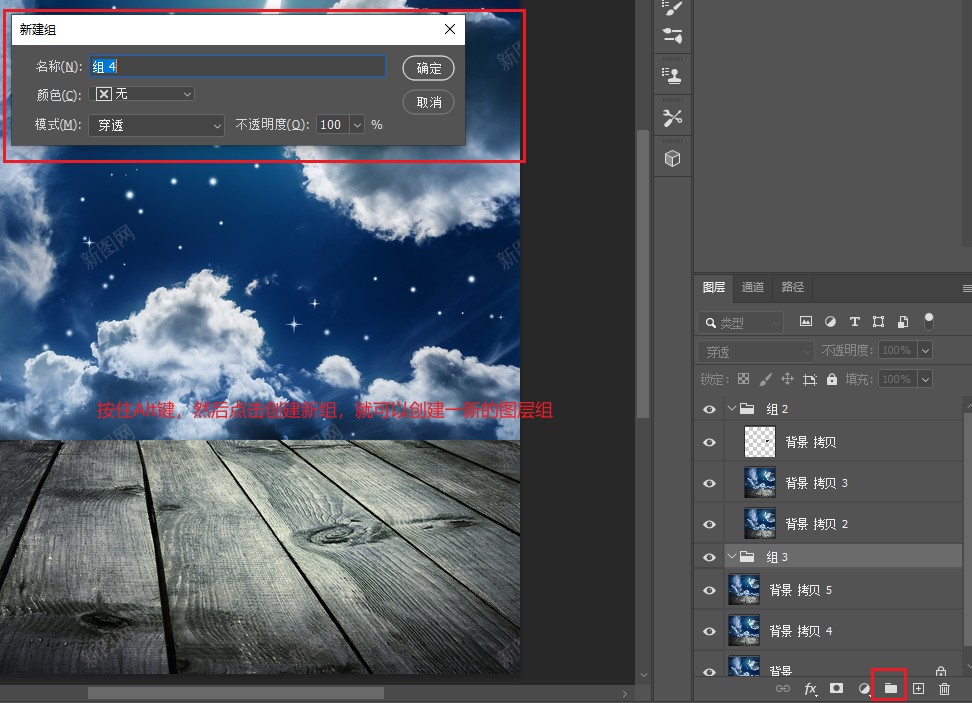
方法三:
快捷键:Ctrl+G
可以修改编组的提示颜色
选择组前面的眼睛按钮,然后右击鼠标,即可弹出颜色选择菜单
如下所示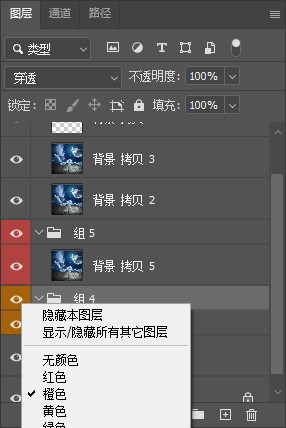
取消编组:
选择组,然后点击鼠标右击,选择取消编组即可
(快捷键Ctrl+Shift+G,但是和搜狗输入法快捷键会有冲突)
图层编组可以整合管理,并具有多种统一属性。
图层整合属性参考图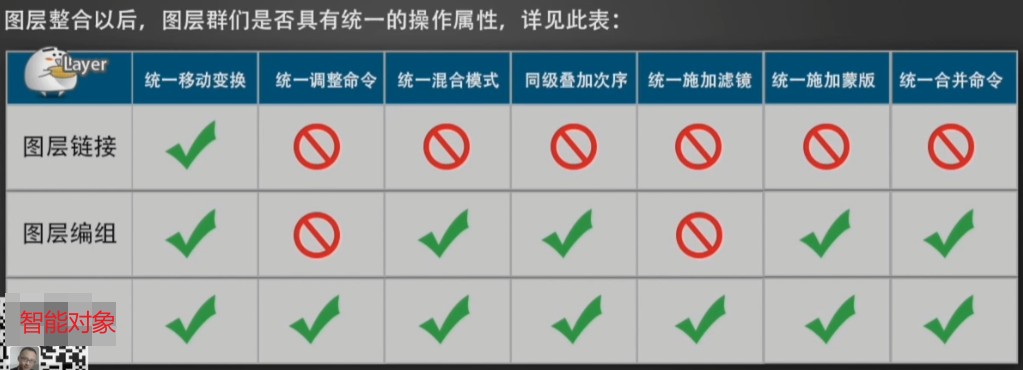
图层合并命令:
选中要合并的图层,然后输入Ctrl+E,即可将几个图层合并
保留旧图层,并与其他图层合并:
Ctrl+Alt+E
合并所有可见图层:
Ctrl+Shift+E
盖印图层:
Ctrl+Shift+Alt+E
所有可见图层拼合效果的新图层
随着智能对象的出现,盖印功能其实越来越濒临淘汰。
(24)图层复合面板
图层复合:保存当前图层的位置,可见性,样式信息。
相当于当时展示效果的一个快照。
(25)剪贴蒙版
上方图层进入下方图层形状。
下方的图层是蒙版图层;上方的图层是使用蒙版的图层;
方案一:
选中上方的图层,然后按住Ctrl+Alt+G
就可以实现剪贴蒙版。
操作及效果如下

方案二:
在已经有剪贴蒙版的情况下,
按住Alt键,右键鼠标拖拽想要新进入蒙版的图层,到鼠标出现一个小矩形框,
然后再左键点击鼠标,那么就可以快速将新图层拖入下方的图层蒙版里。
https://www.bilibili.com/video/BV187411Z7bx/?p=11&spm_id_from=pageDriver&vd_source=7dc3f0bd6dd2626fdbf180d0632d1d01
https://www.bilibili.com/video/BV187411Z7bx/?p=16&spm_id_from=333.880.my_history.page.click&vd_source=7dc3f0bd6dd2626fdbf180d0632d1d01
//自制画笔,工具预设等
为了评估各种边缘检测算法的优劣,我们需要制作一些已知边缘的测试图像,这里记录如何制作评估算法优劣的测试图
构造用于评估边缘检测算法优劣的测试图像源码
https://github.com/ThranduilELFKING/study-openCV/tree/main/makeTmpl
输出效果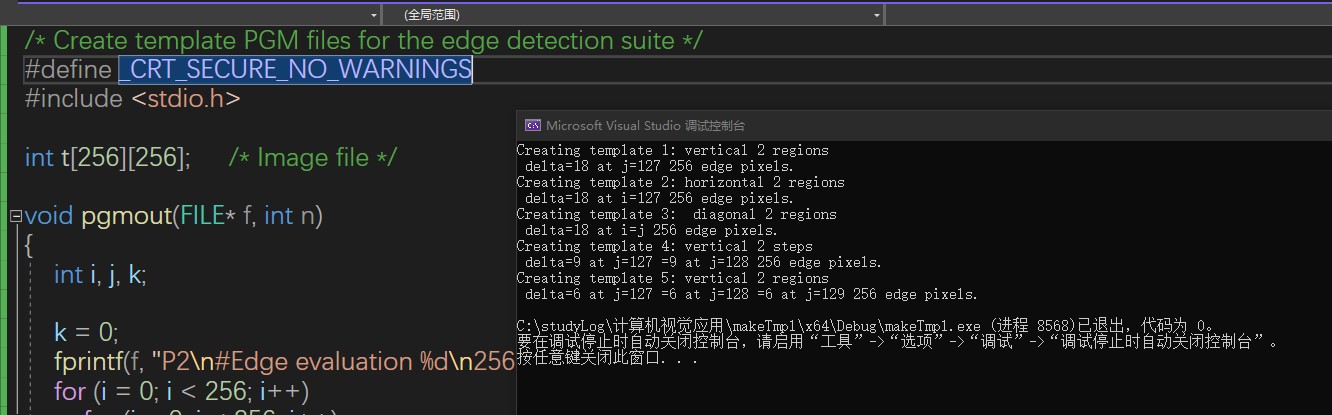
目前,我们习惯了由亮度变化产生的边缘,亮度是由灰阶值来表示的。在现实问题中,需要进行边缘检测的场景中,这种边缘占据了大约90%,但不全是。
事实上,由于颜色的变化,或色相(Hue)的变化,并不总是能被这些边缘检测器检测出来。
如果边缘是对象的边缘,那么单独由颜色标记的边缘应该是能被检测出来,而且由于大部分图像是彩色的,因此在寻找边缘的时候考虑颜色是很重要的。
彩色边缘的检测有主要有两种方法。
方法一:一种方法是将已经讨论的这些边缘检测器应用于每一种颜色通道——红、绿、蓝——然后将这3个结果合并为一个1个结果。
方法二:另一种方法涉及了多维梯度,或偏导数。
方法一很直观,而且很容易实现。
常见的边缘检测方法可用于任何灰阶图像,而图像的红、绿和蓝色分量其实也是灰阶图,只要考虑8字节像素即可。
对于大部分视觉任务来说,RGB值不如一些其他色彩编码方案的原因在于,RGB值包含明显的强度比例。
每一个颜色分量都是那种颜色在整个像素中的强度,而强度则是其他边缘检测器识别的内容。
需要有一种更纯净的颜色表示方法,使得能够通过微分算子找到彩色边缘
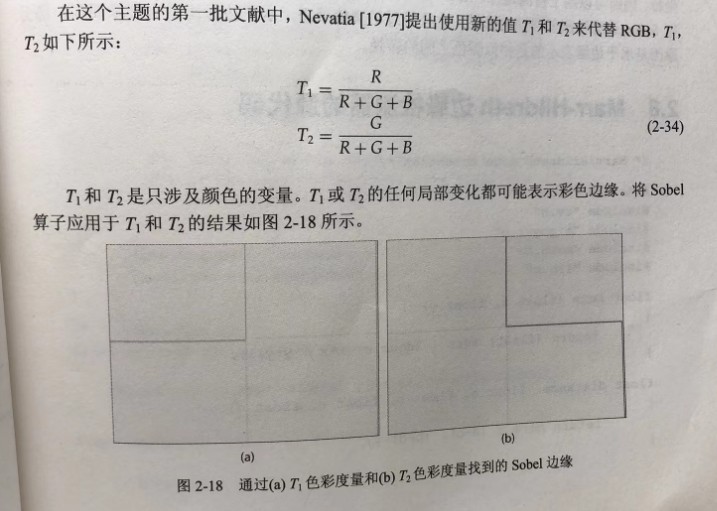
一种更传统(也更困难)的计算方式是找出色相,即像素中的颜色分量的值。
色相是HSV色彩系统中的“H”,可以在很多地方找到对HSV的描述。
其基本思想在于:彩色像素由值(value,V,表示强度)、饱和度(saturation,S,表示色彩的量)以及色相(hue,H,表示色彩的性质)进行描述。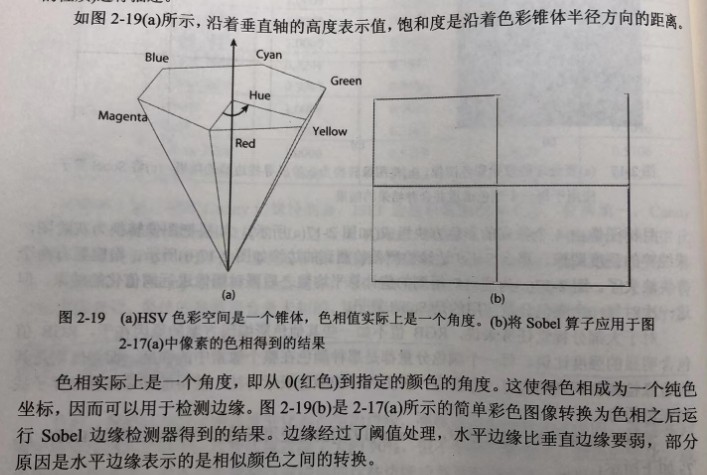
包含RGB、T1和T2、HSV三种方案的边缘检测算法源码
https://github.com/ThranduilELFKING/study-openCV/tree/main/colorEdge
运行起来,示例图像:
RGB方案检查到的边缘:
T1和T2方案检查到的边缘: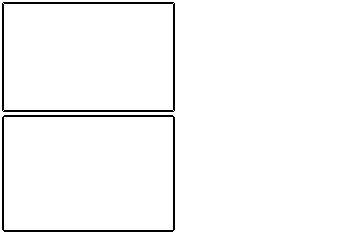
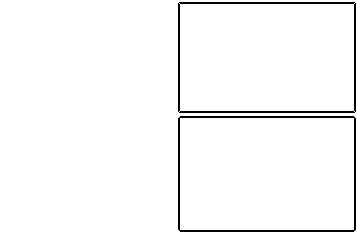
HSV方案检查到的边缘:
Canny边缘检测器是根据一组特定的标准进行优化定义的。尽管这些标准足够合理,但是没有理由认为这些标准就是唯一的标准。
最优的概念是相对的,而且很可能(在某些情况下)存在比Canny边缘检测器更好的边缘检测器。
事实上,在对边缘检测的方法进行比较,有时候看上去实际上是对优化的定义进行比较。
Shen和Castan在边缘检测器的基本形式上与Canny意见一致:首先利用平滑核(smoothing kernel)进行卷积运算,然后再搜索边缘像素。然而,他们通过分析得到了一个不同的函数进行优化:即提出了最小化(在一个维度上)优化:




(1)操作区别
Canny算法通过高斯函数的导数对图像进行卷积运算,然后执行非极大值抑制和滞后阈值操作。
Shen-Castan算法通过无穷对称指数滤波器对图像进行卷积运算,计算BLI,抑制负零交叉,执行自适应梯度阈值操作,最后应用滞后阈值操作。
(2)用户可定义参数不同
这两种算法都提供了用户可定义参数,因此对于使用特定类型图像的调优很有用。
参数如下: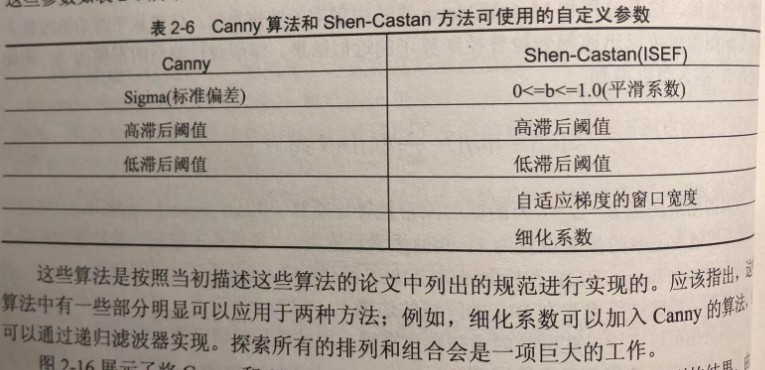
(3)卷积实现不同
由于Canny的实现在执行卷积的时候使用了环绕式的方法(wrap-around),因此在图像边界周围的区域被黑色像素占据,尽管有时候这些黑色像素看上去像噪声。
ISEF实现使用了递归滤波器,环绕式的方法更难实现,因此没有实现,而是采用了另一种方式:图像在处理之前被嵌入了一幅更大的图像。因此,当卷积掩模超出了图像边界的时候,这些图像的边缘几乎都为白色。
(4)噪声的影响
ISEF随着噪声的增大看上去似乎具有优势。
从整体上来说,相比Canny边缘检测器,ISEF边缘检测器略胜一筹,位居第一,Canny位居第二。Marr-Hildreth位居第三,之后是Kirsch,Sobel,△2和△1。
值得注意的是,Canny与ISEF算法的比较的结果取决于用户可定义参数中每个参数的选择,选择的参数更好获得的评估结果可能会更好。
在一些情况下,Canny边缘检测器会更好,而有的时候ISEF方法会占据优势。
对于某个特定的图像来说,最佳的参数组合是未知的,因此最终还要用户自己来选择使用哪一种方法。
Shen-Castan算法源码
https://github.com/ThranduilELFKING/study-openCV/tree/main/isef
David Marr表示:“早期视觉处理的目标是对图像构建一个原始但丰富的描述,用于确定可视表面的反射系数和光强度,以及它们相对于观察者的方向的距离”。
他把最低级别的描述称为原始要素图(primal sketch),其中最主要的组成部分即为边缘。


对比导数算子,基于模板的边缘检测,Marr-Hildreth边缘检测器在低信噪比的情况下要远好于前面两类边缘检测器。
某些情况,由于方法本身的问题,局部性并不是特别好,而且边缘并不总是很细。
Marr-Hildreth算法源码:
https://github.com/ThranduilELFKING/study-openCV/tree/main/marr
基于模板的边缘检测背后的思想,是将一个小的离散的模板作为边缘的模型。
模板既可以尝试对边缘的灰阶的变化进行建模,也可以尝试近似一个导数算子(这种方式最为常见)。
基于模板的边缘检测器的数目非常多,常见的有两种,因为这两种检测器在使用小模板的时候能够获得的边缘像素集合质量最高。
(1)Sobel边缘检测器
(2)Kirsch边缘检测器
Sobel边缘检测器,使用具有如下值的卷积掩模(convolution mask)作为模板: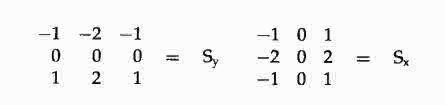
可以把这些模板看做某一个像素上的梯度,这个像素对应模板的中心位置。
注意,对角线上的元素的权重值比水平方向和垂直方向上的元素的权重值要小。
Sobel算子的x分量为Sx,y分量为Sy;把这些分量看做梯度意味着么一个像素的强度和方向可以用梯度向量的数学公式来计算。
数学公式2-6如下: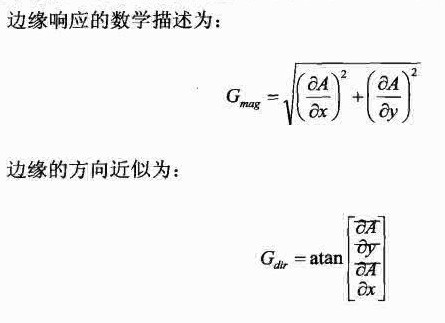
对于一幅图像中坐标为(i,j)的像素来说,Sx和Sy可以通过以下公式计算: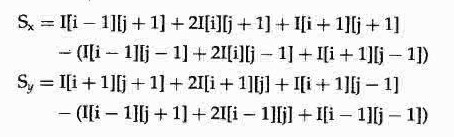

Kirsch算法,使用的模板的目标和Sobel中使用模板的目标不同。对于3x3的例子来说,模板表述如下: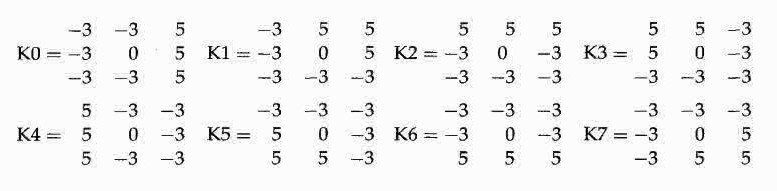
这些掩模试图对多种方向边缘周围的灰阶变化类型进行建模,而不是对梯度的近似。
8个罗盘方向的每一个方向都对应了一个掩模。
(例如,对掩模K0的大响应表示在对应掩模中心位置的像素为垂直边缘(水平梯度)。)
为了找出边缘,要在图像I的每一个像素位置对所有的掩模进行卷积运算。算子在一个像素的响应为这8个掩模响应中的最大值。
每一个边缘像素的方向可以量化为这8种可能性,值为π/4*i,其中i为具有最大响应的掩模编号。
从评估结果和测试图像的外观来看,Kirsch算子应该是这两种模板算子中表现最好的,不过两者的结果非常相似。
这两种模板算子的表现结果都比简单的导数算子要好,特别是在噪声增加的情况下。
注意,在目前研究的所有情况中,边缘检测算法中没有指名的因素会对检测的效果造成影响。
其中重要的因素包括阈值方法的选用,但是有时候在检测之前会进行简单的去噪操作,在检测之后会进行边缘细化操作。
Sobel算法
https://github.com/ThranduilELFKING/study-openCV/tree/main/sobel
Kirsch算法
https://github.com/ThranduilELFKING/study-openCV/tree/main/Kirsch
由于边缘是由灰阶值的变化定义的,因此对这种变化敏感的算子就可以用作边缘检测器。
导数算子是可以实现这种功能的:
导数的意义之一就是表示函数值的变化率,而图像中的灰阶值的变化率在边缘附近很大,在常量区域很小。
由于图像是二维的,因此应该考虑很多方向上的灰阶值变化。基于这个原因,我们采用了图像关于主方向x,y的偏导数。
对边缘实际方向的估计可以将x方向和y方向的导数看做实际方向上沿两条轴的分量,然后通过计算向量和得到。
这里使用的算子刚好是梯度(gradient),如果把图像看做是一个二变量的函数A(x,y),那么梯度可以定义为: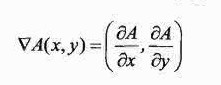
这是一个二维向量。
当然,一幅图像不是一个函数,因而不能通过这种方式进行求导。
由于图像是离散的,因此我们使用差分运算,即:一个像素点的导数可以由一块局部区域内灰阶值的变化来近似。
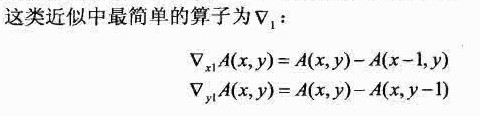
这种情况的假设为灰阶值在像素之间线性变化,因此不论在哪里取导数,导数的值都是直线的斜率。
这种近似的问题在于斜率的计算并不是在点(x,y),而是在(x - 1/2, y - 1/2)点处。
因此,边缘的位置会在原来的基础上向-x和-y方向偏移半个像素。
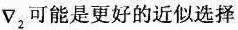
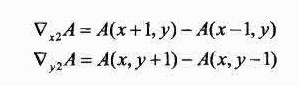
这个算子关于像素(x,y)是对称的,不过没有考虑像素(x,y)的值。
不管采用什么算子来计算梯度,得到的向量都能表示边缘在那个像素处的强度以及边缘的方向。
梯度向量的长度为一个直角三角形斜边的长度,而这个长度反映了给定像素上的边缘强度(或称边缘响应,edge response)。
在这个像素上边缘的方向为直角三角形斜边和轴的夹角。
边缘大小的值为一个实数,通常通过取整操作转换成整数。
任何像素的梯度值如果超过了一个指定的阈值,这个像素就被称为一个边缘像素,而其他像素则不是。
(一般,会将一定范围内的灰阶值的中值作为阈值)
从技术上说,边缘检测器只会报告出边缘像素,而边缘增强操作将边缘像素绘制在原始图像上。
边缘增强的测试图像能够粗略的表明边缘检测算法的成功性。
我们需要一个能够绝对表示边缘检测方法好坏的数值度量值用于评判。通常来说,没有这样的度量。
对边缘检测器可能失败或出错的方式,我们进行思考:
(1)首先,边缘检测器可能在没有边缘存在的时候报告边缘,可能的原因包括噪声、阈值和糟糕的设计,这种情形称作错误肯定(false positive)。
(2)此外,边缘检测器也可能在存在边缘像素的地方没有报告边缘的存在,这种情形称作错误否定(false negative)。
(3)最后,边缘像素的位置可能是错误的。
能够报告出边缘像素正确位置的边缘检测器显然比那些无法报告出正确位置的要好,因此我们找些测试图像,这些测试图像的边缘像素的数目和位置都是已知的,而且应用噪声的类型和数量都是已知的,因此对这些标准图像应用边缘检测器可以给出这些边缘检测器效果好坏的近似评估。
这种方法,考虑的是边缘的实际位置。
这种方法基于局部边缘一致性(local edge coherence)。
这种方法并没有考虑边缘的实际位置,因此是Pratt度量的一种补充。
这种方法考虑的是边缘像素和局部周边边缘像素的匹配程度。
(1)首先,定义了一个函数,测量一个边缘像素在左侧的连续性如何,这个函数如下所示:
(2)还有一个类似的函数,用于测量一个边缘像素在右侧的连续性如何,如下所示:
(3)然后在应用一个细度的测度。
边缘应该是一条细线,即1个像素宽。更大宽度的线条表示存在错误肯定的情况,原因可能是因为边缘检测器对同一个边缘进行了多次响应。
细度T的度量表示的是以要测量的像素为中心的3x3区域中的6个像素,即去除中心像素和L(k)和R(k)找到的两个像素(边缘像素)得到的6个像素。
(4)边缘检测器的整体评估函数如下所示: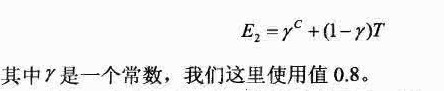
导数算子方案一:
https://github.com/ThranduilELFKING/study-openCV/tree/main/gradient1
导数算子方案二:
https://github.com/ThranduilELFKING/study-openCV/tree/main/gradient2
pratt测试法:
https://github.com/ThranduilELFKING/study-openCV/tree/main/pratt
KR测试法:
https://github.com/ThranduilELFKING/study-openCV/tree/main/kr
边缘检测是图像分析中使用到的最常见的操作之一,边缘增强(edge enhancement)和边缘检测(edge detection)相关的算法可能是最多的。
这里对边缘检测算法做个大致的分析。
从广义上来说,其原因在于边缘形成了一个对象的轮廓。对象是图像分析和视觉系统中重要的处理主体。边缘是对象和背景之间的边界,还能表示重叠对象之间的边界。
这意味着,如果图像中的边缘可以准确地被识别出来,那么所有的对象都可以被定位,而且对象的基本属性(例如面积、周长和形状)都可以被测量出来。
由于计算机视觉要涉及图像中对象的识别和分类,因此边缘检测成了一个基本工具。
注意,无法判断图像中哪一部分为背景、哪一部分为对象,只能识别出各个区域之间的边界。
边缘检测被称作图像分割(segmentation)的过程的一部分——图像分割的目的是识别出图像中的区域(region)
从技术上说,边缘检测是定位边缘像素的过程,而边缘增强是增加边缘与背景之间的对比度以便能够更清楚的看清边缘的过程。
在实践中,这两种术语经常互换使用,因为大部分边缘检测程序也会把边缘像素的值设置为特定的灰阶或颜色,使得边缘更容易被识别。
边缘跟踪(edge tracing)是沿着边缘进行跟踪的过程,这个过程通常会把边缘像素采集到一个列表中。这个过程以一个一致的方向进行,既可以顺时针,也可以逆时针绕着对象旋转。
链码算法(Chain coding)是边缘跟踪算法的一个特例。这种算法得到的结果是对象的一个非光栅表示,可以用于计算形状测量,或者对对象进行识别或分类。
经典的两种边缘检测算法是:Canny边缘检测器和Shen-Castan边缘检测器(也称作ISEF边缘检测器)。
这两种检测器都有坚实的理论基础,而且都声称具有一定程度的最优性;也就是说,这两种检测器都在特定的场景下可以达到最好效果。
具体这两种检测算法,可以看后续blog
大部分好的算法都会事先声明清楚能够解决的问题,并且的都会对解决问题的方法以及方法能够正确工作的条件进行有说服力的的分析。
在这个框架基础下,要定义一个的边缘检测算法意味着首先要定义什么是边缘,然后利用这个定义提出边缘增强和边缘识别应该采用的方法。
边缘可能有多种定义,每一种定义都适用于某些特定的场合。
理想阶梯型边缘(ideal step edge)是一种最常用也最有一般性的定义。如下图所示: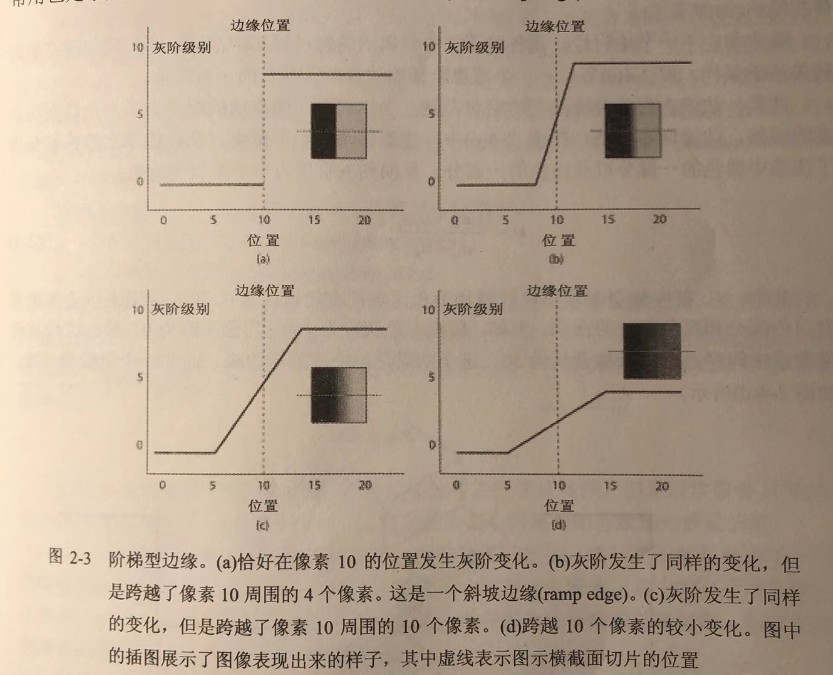
这里看出,边缘只不过是在某个位置发生的灰阶变化。
灰阶变化越大,边缘的检测也就越容易(不过在理想的情况下,任何灰阶变化都可以很容易地看出来)。
边缘检测的难点主要有两个:
(1)第一个难点来自于数码化。
图像的采样不可能使得整个边缘刚好落在像素边界上。事实上,灰阶的变化可能遍及多个像素(如图2-3的(b)~(d)所示)。
可以认为边缘的实际位置在连接低灰阶与高灰阶的斜坡(ramp)中央。这个斜坡只是数学意义上的斜坡,因为在图像数码化(采样)之后,这个斜坡实际上呈现的是阶梯锯齿状。
(2)第二个难点来自于无处不在的噪声问题。
由于受到很多因素的影响,例如光强度、相机和镜头的类型、移动、温度、大气效应、粉尘和其他因素,因此在场景中表示同样灰阶的像素很可能在图像中不是同样的灰阶。噪声是一种随机效应,因此只能通过统计的方式特征化。
噪声对图像造成的结果是使得有些像素的灰阶值产生随机的变化,因此理想边缘中的平滑线条和斜坡在真实的图像中是不可能遇到的。
在没有噪声的情况下,任何明显的灰阶变化都可以表示边缘。
在图像中几乎不可能真正遇到阶梯型边缘,因为:
(1)对象很少有如此清晰的轮廓;
(2)场景的采样永远都不会让边缘正好位于像素的边缘上;
(3)存在噪声
斜坡是一个模型,它表示为了产生台阶,边缘本应该是什么样子,因此这是一个理想化的情况,而实际上遇到的是数据插值的结果。
尽管理想的阶梯边缘和斜坡边缘模型在过去通常用来设计新的边缘检测器,但是这种模型是一种简化的模型。
任何图像获取的过程都可能会产生某种类型的噪声,因此忽略噪声是没有意义的。没有噪声的理想情况在实践中永远也不会发生。
由于噪声的随机本质,因此无法准确的对其进行预测,而且无法在一个有噪声的图像中准确测量噪声,因为无法区分噪声对灰阶的影响以及像素数据对灰阶的影响。
然而,有时候可以通过噪声对图像造成的效果来对噪声进行特征化。
噪声的特征通常可以用带有特定平均值(mean)和标准偏差(standard deviation)的概率分布来表示。
在图像分析中,特别关注的是以下两种类型的噪声:
(1)信号无关的噪声(signal-independent noise)
(2)信号相关的噪声(signal-dependent noise)
信号无关的噪声是一组随机的灰阶值,在统计意义上和图像数据无关,这些数据加入图像的像素中产生了带噪声的图像。
当一幅图像通过电信号的方式从一处传输到另一处的时候会产生这种噪声。
令A为完美图像,N为传输过程中产生的噪声,那么最终得到的图像B为: B = A + N
A和N互相没有关系。噪声图像N可能没有任何统计属性,但是通常假设N符合正态分布(高斯分布),其中平均值为0,标准偏差为某个测量到的值或者预先假设的值。


在这种情况下,图像中每一点的噪声值的大小为这一点灰阶值的函数。
一些照片中的颗粒就是这种噪声的例子,而这种噪声通常都比较难以处理。不过幸运的是,这种情况不是太重要,如果照片采样合适的话,这种情况也是可以处理的。
很难在各种不同的随机情形中都找到边缘,但是一个好的边缘检测器在这种情况下也应该能够判断边缘的位置。
边缘是由灰阶(或色彩)等高线定义的。穿过等高线的时候,灰阶值会迅速变化;沿着等高线走,灰阶值的变化会更加轻柔,有可能是随机变化。因此可以得出结论:边缘具有一个可测量的方向。
边缘像素和噪声像素都具有的特点是,相比周围像素有明显的灰阶变化。
而边缘像素互相连接,构成了等高线,因此可以通过这一个特性将边缘像素和噪声像素区分开来。
3种常见的算子可以用于定位边缘。
(1)导数算子
这种算子被设计为标识发生巨大强度变化的地方。
(2)类似于模板匹配的方案
其中边缘由一个很小的图像进行建模,这个图像表现出了完美边缘的抽象属性。
(3)使用边缘的数学模型
其中最好的也使用了噪声模型,并且努力吧噪声因素考虑进去。
这一种类型的算子,是我们主要需要关注的。
给图片添加噪声的算法代码:
https://github.com/ThranduilELFKING/study-openCV/tree/main/makenoise
估计噪声的算法代码:
https://github.com/ThranduilELFKING/study-openCV/tree/main/measurenoise
缺失模块。
1、请确保node版本大于6.2
2、在博客根目录(注意不是yilia根目录)执行以下命令:
npm i hexo-generator-json-content --save
3、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: false
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true