
字符及文件操作函数一
背景
对文件操作,做一个整体的记录整合
EOF标识
EOF(-1)
end of file 文件结束标志
键盘上用 ctrl + z 实现
EOF是一个计算机术语,为End Of File的缩写,在操作系统中表示资料源无更多的资料可读取。资料源通常称为档案或串流。通常在文本的最后存在此字符表示资料结束。
这个定义的意思是,文档的结尾都有一个隐藏字符”EOF”,当程序读取它的时候,就会知道文件已经到达结尾。通常使用while循环加EOF判断作为读取结束的标志。
EOF 的值通常为 -1,但它依系统有所不同。
getchar函数
函数头文件及原型
1 | #include <stdio.h> |
函数说明:
字符输入函数,没有参数,从输入缓冲区里面读取一个字符
一次只能读取一个字符
该函数以无符号 char 强制转换为 int 的形式返回读取的字符,如果到达文件末尾或发生读取错误,则返回 EOF(-1)
示例代码
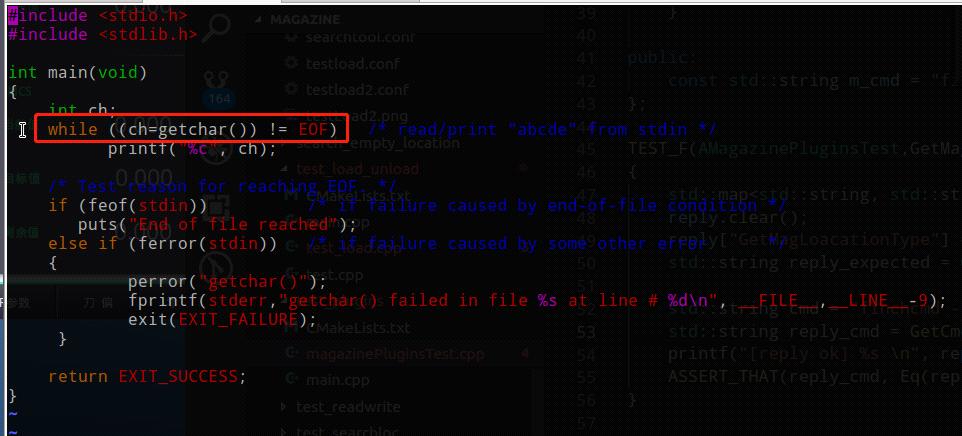
编译后执行
原理分析
程序的运行过程是这样的,getchar 有一个 int 型的返回值。
当程序调用 getchar 时,程序就等着用户按键。用户输入的字符被存放在键盘缓冲区中,直到用户按回车为止(回车字符 \n 也放在缓冲区中),当用户键入回车之后,getchar() 函数才开始从输入缓冲区中每次读取一个字符,getchar 函数的返回值是用户输入的字符的 ASCII 码,若遇到文件结尾 (End-Of-File) 则返回 -1 (EOF),并将用户输入的字符回显到屏幕,如果用户在按回车之前输入了不止一个字符,其他字符会保留在键盘缓存区中,等待后续 getchar 调用读取。也就是说,后续的 getchar 调用不会等待用户按键,而直接读取缓冲区中的字符,直到缓冲区中的字符读完后,才等待用户按键。程序中 while 循环工作时,每一次循环 getchar() 就会从输入缓冲区读取一个字符,然后 printf 输出,直到遇到了文件结束标志 EOF,循环判断条件为假,循环才结束.
为啥用缓冲区呢?
因为计算机CPU的处理速度是很快的,我们用键盘输入速度比不上CPU的处理速度,CPU就得等键盘输入完,很浪费资源,所以,当键盘输入完了,让CPU一次性处理,可以大大提高效率。
getchar与scanf函数的区别
对于 scanf 函数,’\n’ 会触发 scanf 读取输入缓冲区的内容,当遇到 字符’\n’ 或空格 ‘ ‘ 会停止读取,而 getchar 会直接读取 ‘\n’ 和空格
feof函数
函数头文件及原型
1 | #include <stdio.h> |
函数说明:
eof()是检测流上的文件结束符的函数,如果文件结束,则返回非0值,否则返回0
一般在文件操作,中经常使用feof()判断文件是否结束。
示例代码:
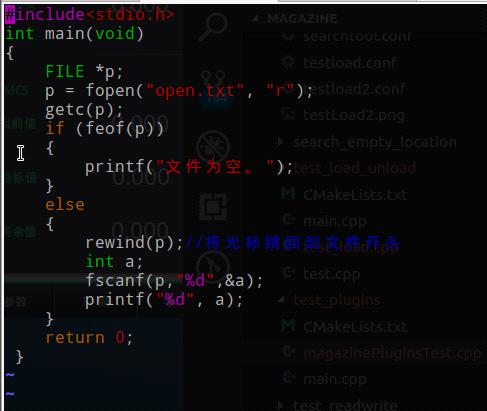
原理分析
feof()函数,并不是通过读取到文件的EOF来评判,这个文件是否为空。
对feof()来说,它的工作原理是,站在光标所在位置,向后看看还有没有字符。如果有,返回0;如果没有,返回非0。它并不会读取相关信息,只是查看光标后是否还有内容。
对于文件来说,无论是空文件,还是存有信息的文件,当文件被打开,光标处于默认的开头时,光标后都有信息,这时候调用feof()来查看光标后是否还有内容,就没意义。
所以我们需要先使用getc(),从文件中读取一个字符,让光标向后移动一个字符。这时空文件的光标就已经移动到EOF的后面,这时使用feof()就会返回1了。这才是feof()的正确用法。
但是要注意,一定要将光标回到文件的开头,因为之前判断文件是否为空时,将光标向前移动了一位,必须要将光标恢复到开头,这样才能保证文件的正常读取。
ferror函数
函数头文件及原型
1 | #include <stdio.h> |
函数说明:
检测流上的错误,若检测到给定流上的错误,返回非0;无错误,返回0。
isalpha函数
函数头文件及原型
1 | #include <ctype.h> |
函数说明:
用来检测一个字符是否是字母,包括大写字母和小写字母。
参数 c 表示要检测字符或者 ASCII 码。
返回值:返回非 0(真)表示 c 是字母,返回 0(假)表示 c 不是字母。
isdigit函数
函数头文件及原型
1 | #include <ctype.h> |
函数说明:
参数 c 表示要检测的字符或者 ASCII 码。
返回值:返回值为非 0(真)表示 c 是数字,返回值为 0(假)表示 c 不是数字。
touppper函数
函数头文件及原型
1 | #include <ctype.h> |
函数说明:
把小写字母转换为大写字母,不是小写字母的不变
参数: int ch 待转换的字符
返回值: 返回转换后的字符
seekp函数
文件流对象有两个成员函数,分别是 seekp 和 seekg。它们可以用于将读写位置移动到文件中的任何字节。
seekp 函数用于已经打开要进行输出的文件。
可以理解为seekp 可用于将信息 put(放入)到文件中。
以下是 seekp 的用法示例:
1 | file.seekp(20L, ios::beg); |
第一个实参是一个 long 类型的整数,表示文件中的偏移量。这就是想要移动到的字节数。在该示例中,使用的是 20L(请记住,L 字符可以强制编译器将该数字视为一个 long 类型的整数)。该语句可以将文件的写入位置移动到编号为 20 的字节(所有编号从 0 开始,因此编号为 20 的字节实际上是第 21 个字节)。
第二个实参称为模式标志,它指定从哪里计算偏移量。标志 ios::beg 表示偏移量是从文件开头算起的。也可以修改该参数,从文件末尾或文件中的当前位置计算偏移量。表 1 列出了所有 3 种随机访问模式的标志。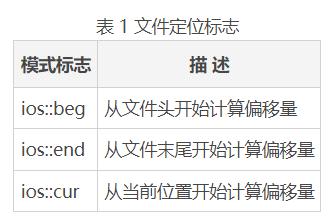
表 2 显示了 seekp 和 seekg 使用不同模式标志的示例。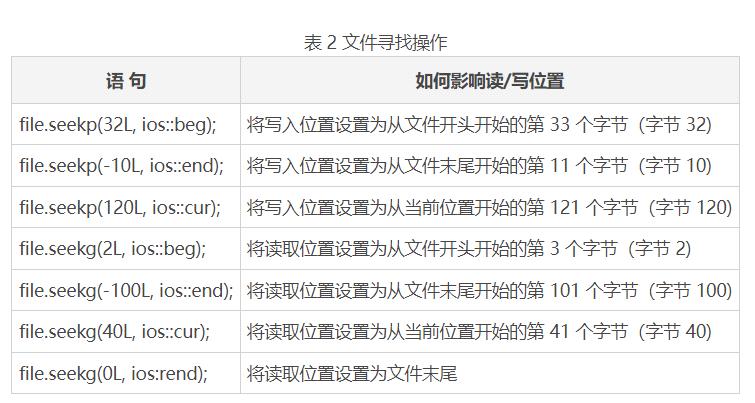
seekg函数
seekg 函数则用于已经打开要进行输入的文件。
seekg 则可用于从文件中 get(获取)信息。
ifstream之eof函数
推荐写法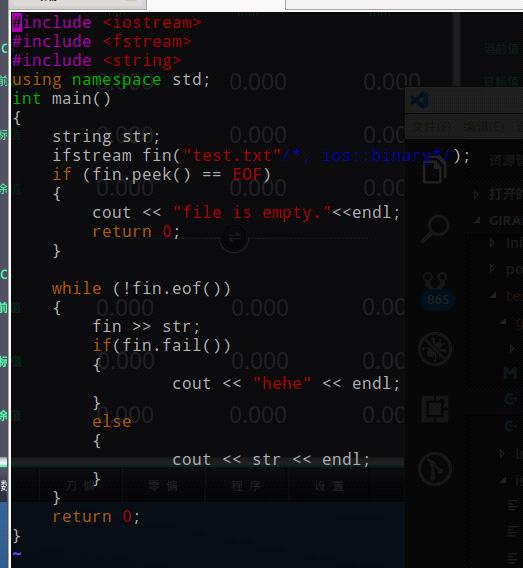
参考链接
https://blog.csdn.net/weixin_48025315/article/details/119381482
https://en.cppreference.com/w/c/io/getchar
https://en.cppreference.com/w/c/io/feof
https://blog.csdn.net/konghouy/article/details/80530937
https://en.cppreference.com/w/c/io/ferror
http://c.biancheng.net/view/1541.html
https://blog.csdn.net/Nine_CC/article/details/107166518
https://blog.csdn.net/rebel_321/article/details/4927464